
Search-Guided, Lightly-Supervised Training of Structured Prediction Energy Networks
Published in Neurips, 2019
Recommended citation: Rooshenas, A., Zhang, D., Sharma, G., McCallum, A., ." Neurips 2019 1 http://rooshenas.github.io/files/sg_spen_neurips2019.pdf
This paper is about training SPENs using indirect supervision that comes from reward functions. Download paper here
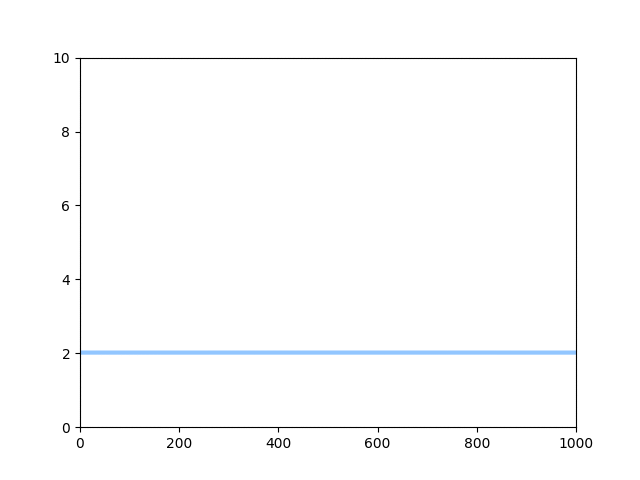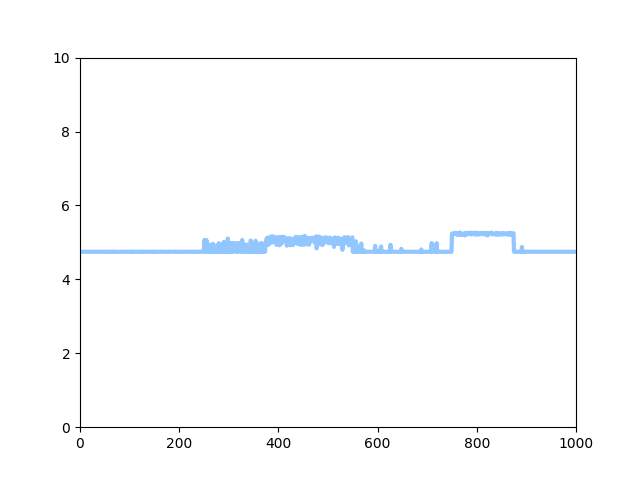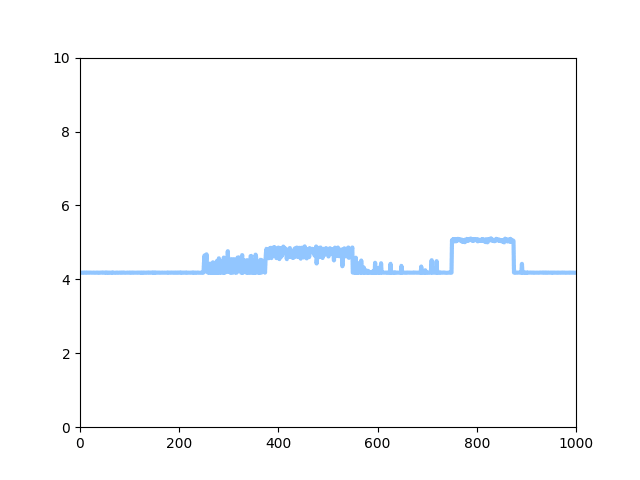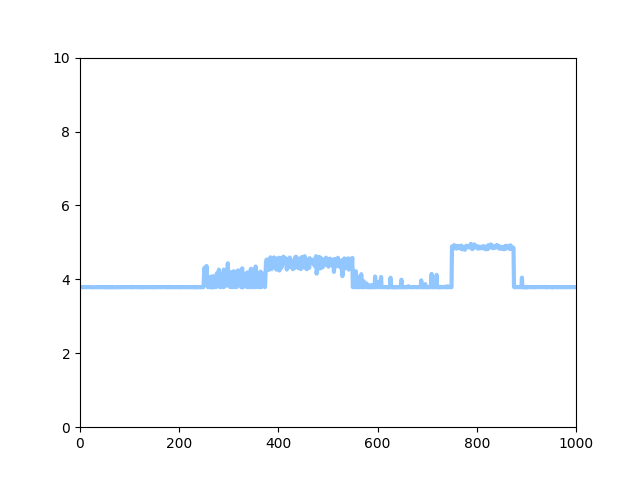
Here I show the behavior of SG-SPEN on a toy 1-D dimensional problem, in which we have one output variable of 1000 dimension. The reward function shows the reward value for each of these dimensions that the output variable can take.
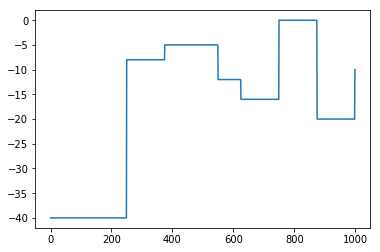
I plot the negative of the energy values during training. As we can see, the energy function approximates the relative position of important local optima.
Here is a short video that describes the algorithm: